Nota del autor: Todos los contenidos de este artículo son extractos del libro “The Data Engineer’s Guide to Apache Spark” que puedes descargar desde la pagina de databricks: https://databricks.com/lp/ebook/data-engineer-spark-guide
Preludio:
Cluster:
Un cluster no es más que un conjunto de máquinas trabajando de forma coordinada. Un cluster de Spark se compone de nodos. Uno actúa como DRIVER y es el punto de entrada para el código del usuario. Los otros actúan como EXECUTOR que seran los encargados de realizar las operaciones.
Spark Session:
Es el objeto que tenemos para controlar nuestra aplicación de Spark. En Scala la variable “spark” representa este valor. Podemos generar esta sesión de SparkSession a traves de un “builder”. (Aquí podremos inyectar configuraciones, etcétera).
Nota: Spark Session apareció como estándar en Spark 2.0, antes de esto se utilizaba un “Spark Context” que nos permitía solamente crear RDD’s. Si queríamos hacer algo con sql había que instanciar un sqlContext, para hive un hiveContext… Para más información, este artículo lo describe muy bien: https://medium.com/@achilleus/spark-session-10d0d66d1d24
Conceptos de tipos de datos:
DataFrame:
Es una representación de una tabla con filas y columnas. Podemos encontrar las columnas que contiene un dataframe y el tipo de las mismas en la propiedad schema. La ventaja de un dataframe es que puede estar distribuido a lo largo de decenas de máquinas. Es la forma más sencilla de trabajar con datos en Spark y tiene la ventaja de contar con un optimizador (Catalyst).
Datasets:
Son otra representación de datos pero tipados. Como “truco” un dataframe es un dataset de un tipo abstracto llamado “Row”.
RDD:
Son la primera aproximación que se hizo para computar datos de forma distribuida. De hecho se puede acceder al rdd de un dataframe. Se desrecomienda su uso por su “fragilidad” y porque la api de DataFrame ya ha igualado a la de RDD.
Conceptos de operaciones:
Particiones:
A diferencia de una partición de Hive (una carpeta con datos que podemos “esquivar” al hacer consultas) estas particiones son trozos de datos. Una serie de filas que residen en la misma máquina fisica. Para ajustar el numero de particiones disponemos de los métodos repartition y coalesce. La información sobre el impacto que tiene esto puede ver en Conceptos de Ejecución -> Tareas.
Transformaciones:
Son las instrucciones que podemos utilizar para modificar un dataframe. Una transformación no da ningún resultado ya que se evalúa mediante “lazy evaluation”, es decir, puedes encadenar operaciones que hasta que no ocurra una “acción”, estas transformaciones no se computan. De esta forma, Spark es capaz de organizar las transformaciones para dar el mejor plan de ejecución físico posible y ahorrar la mayor cantidad de “shuffling” (intercambiar datos entre nodos).
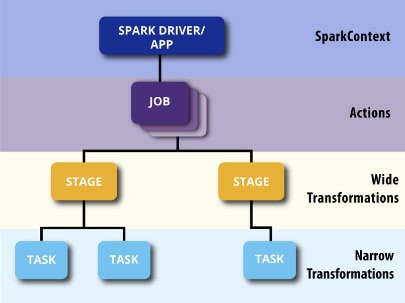
Acciones:
Son las instrucciones que hacen que se computen las transformaciones previas. La más simple puede ser un count. Pero son acciones cosas del tipo: un show para mostrar los datos, un write para escribir un output, un collect para devolver los datos al nodo driver.
Conceptos de ejecución:
Jobs:
Una acción desencadena un job para computar las operaciones. No es mas que una unidad de organización lógica.
Stages:
Son “pasos” en una ejecución, basicamente agrupan tareas y resolven dependencias entre sí.
Tasks:
Es la unidad de ejecución de cualquier worker y la que trabaja con los datos directamente haciendo uso de los recursos. Esta directamente relacionada con el concepto de partición.
Extra
En la web de https://supergloo.com/spark/spark-fair-scheduler-example/ se representa perfectamente la jerarquía entre operaciones y ejecución.